A wave of media hysteria has been unleashed by the recent hot and dry “Sahara” weather Europe has seen over the past few weeks. Cries to shut down the coal power plants and to adopt vegan diets have reached peak volume!
ARD Fake News: “CO2 causing lung disease”
The neurosis has gotten so bad, that flagship German media have been reporting new breath-taking claims.
For example Germany’s version of the BBC ARD German public television, here claimed that CO2 is not only “killing the climate”, but is also even “causes lung disease”!
NBC’s Al Roker: Warming now causing less hurricanes!
In the US, NBC meteorologist Al Roker here did have some good news: Global warming is now causing less hurricanes (and not more): The melting Arctic ice is cooling the Atlantic, which works against the formation of hurricanes, he claimed.
Unfortunately that “information” from Mr. Roker has turned out to be really fake. Expert meteorologist Dr. Ryan Maue even called Roker’s outlandish claim “cringeworthy”.
“Not heat problem, rather hysteria problem”
But among the cacophony of hysteria emanating from the global fake news construct, there have been a few remaining voices of sanity – fortunately.
For example journalist/lead commentator Torsten Krauel of Germany’s flag ship national daily Die Welt here wrote an opinion piece titled: “Germany doesn’t have a heat problem, rather it has a hysteria problem.
In the opinion piece Krauel writes:
There have been many hot summers, as well as rainy cool ones. Germany does not have a heat problem, and a look at the past shows this.”
Krauel then reminds the amnesia-prone German readers of the hot spells of the 1990s, or 2006, 1983, 1975, 1963 and 1958 as examples, where periods of heat and/or extreme drought also occurred.
Indeed according to Swiss meteorologist Jörg Kachelmann, July 2006 was much warmer than July 2018, by 2°C.
Going vegan our only hope
Die Welt’s Krauel adds with sarcasm:
But over 2018 in some places they complain like end-of world preachers. It is the largest anomaly since records have been kept. Water will be in short supply, Sea level is rising. Become a vegan, otherwise it will continue like this.”
Cold front erases the hysteria
In the meantime, a cold front has passed through the continent, thus dislodging the blocking high behind the unusually summerlike weather which many had been enjoying.
Central European temperatures today as of 1 p.m. ranged only from the low sixties to low seventies Fahrenheit.
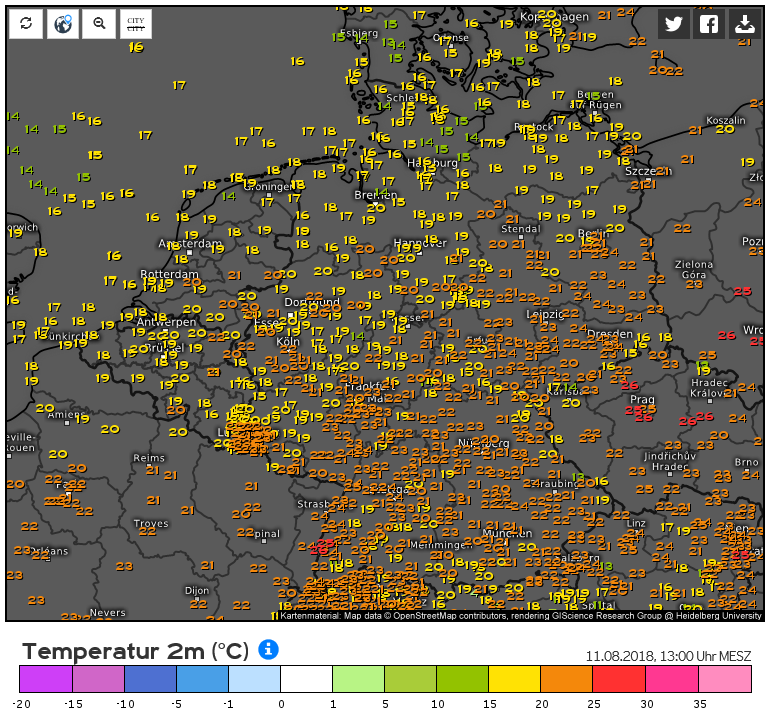
Chart: Kachelmannwetter.de
It won’t be long before we start hearing complaints about all the cool and damp weather and longings for summer.





[…] German Flagship Daily ‘Die Welt’: Germany Has A Hot Weather “Hysteria Problem” […]
CO2 causing lung disease. ROFLMAO !!
What is the concentration of CO2 in our lungs ???
Surly our resident AGW trollette could not even support such nonsense.
We will see. 😉
And of course, there is zero evidence that enhanced atmospheric CO2 is affecting the climate in any way whatsoever, either.
Holy cow! 15-25c That’s the temp range here in northwest New South Wales, Australia, yesterday which is a winter day.
NoTricksZone Readers, I’ve written a post to address the Social Media Censorship I wanted to share with you.
Comprehensive Climate Change Debating Points and Graphics; Bring It Social Media Giants. This is Your Opportunity to Do Society Some Real Good
https://co2islife.wordpress.com/2018/08/11/comprehensive-climate-change-debating-points-and-graphics-bring-it-social-media-giants-this-is-your-opportunity-to-do-society-some-real-good/
You’re right about the censorship.
https://www.thegatewaypundit.com/2018/08/coming-soon-to-the-usa-a-month-before-election-swedens-leftist-govt-obtains-right-to-silence-critics-on-facebook/
https://www.thegatewaypundit.com/2018/08/twitter-permanently-bans-gavin-mcinnes-and-the-official-proud-boys-account/
Why debate, when you can own the narrative.
“Debate? What’s there to debate?”
“The melting Arctic ice is cooling the Atlantic, which works against the formation of hurricanes,” [Al Roker]
I always thought Al was a nice guy.
Maybe he has gotten Alzheimers ! ?
Of course a cooler ocean in the area from 5° North to 15° North Latitude (pick other numbers if you like) will tend to suppress hurricane formation. How cold water from the Arctic would get to that location on the surface is a mystery of biblical stature.
“How cold water from the Arctic would get to that location on the surface is a mystery of biblical stature.”
It’s all quite simple really John F. Hultquist, by employing the Climatariat’s pseudo-scientific prestidigitation of teleconnections.
By this method a consensus is maintained that everything can be explained and are explainable, but without the inconvenience of requiring the underlying process(es) to be measured, or even thoroughly understood.
“… flagship German media have been reporting new breath-taking claims. …[like]…CO2 is not only “killing the climate”, but [it] also even “causes lung disease”!“
HAHAHAHA – Good one.
OT…
I’ve just watched the precision perfect launch of the Parker Solar Probe Mission. Hopefully over the next 7 years of it’s mission, and with data from this probe, we will discover why the sun controls so much of our climate’s variation.
More at https://twitter.com/NASASun
Tell us more about how it didn’t get warmer in Germany! Especially in the summer:
https://www.dwd.de/DWD/klima/national/gebietsmittel/brdras_ttt_14_de.jpg
And while you’re there tell us why winter in cold.
Huh?
https://www.dwd.de/DWD/klima/national/gebietsmittel/brdras_ttt_16_de.jpg
Huh?? seb posts a classic UHI temperature graph with maximum temperatures of 4ºC
Then says its not cold. !! DOH !!
Go away seb, until you have something rational to say.
Stop wasting everyone’s time.
Admit it spikey, you have no idea what you are talking about. You just feel compelled to answer with clown stuff like this to everything I write. Correct?
seb thinks temperature around 0ºC are not cold.
WOW !!!!!
NO wonder he is petrified of a bit of NATURAL warming.
You know the warming is NOT caused by human CO2, because you KNOW that CO2 doesn’t not have any measurable warming effect.
So STOP PANICKING !!!
And enjoy the slight warming.. while it lasts.
You are over there, seb
How about you do a road trip and check the quality of Germany’s temperature sites..
You may even find one or two that are actually up to WMO standards, and don’t have large UHI effects.. if you look really hard.
Here’s a great chance for you to do some cherry picking.
You mean I should go to the nearest station and use my FLIR to measure surrounding concrete plates and buildings on a hot day? Then I imagine myself how these structures have caused increasing temperatures over the time they exist. Every year a few 0.0x °C more, right? That’s what those structures do 😉
Feel free to take a look at station 3015 (Lindenberg) as an example of a rural station. What’s the linear trend of that station?
https://www.dwd.de/DE/leistungen/klimadatendeutschland/klarchivtagmonat.html?nn=16102
Hint: the 30-year mean temperature increased by roughly 1°C in 100 years at that station. UHI effect?
Nah, no development around that site, seb
East and south, newish houses and development, now half urban. So when you get a breeze from the south, .. OOPS, seb faceplants in his own ignorance yet again.
And of course temps just above 0C are so scorchingly hot, right seb. !!
oops , wrong site.
Still waiting for picture of Stevenson screen.
Or did they change to AWS.. if so, when.
And in case you try to belittle the increase of 1°C over 100 years at a rural site (ID 3015), almost all of the increase happened since 1990.
Indeed Spike55,
And the mindless advocates do not think a 1°C rise in 100 years could possibly be natural because….er because…
Well there is no reason, logic, or evidence that it is not natural.
It gets cold in winter and hot in summer, but according to the headless chooks such variations can not be natural, they believe (for that is all they have) these happen because of man-made CO2. No! If history shows anything then it shows that natural process are in control of both weather and climate, not the minuscule effect of humans.
And what history would that be? There is no history of a CO2 increase caused by humans that we can compare the current situation too.
Yeah if you consider humans to be a result of nature, then of course it is all natural. Otherwise, there is no indication that the increase in global temperatures in the last few decades is natural in the sense that it would have happened anyway, e.g. if we would not have been living on this planet.
Is there any threshold that when surpassed you’ll consider the change “not natural”? What would it take? A warming of 2°C? 3°C? More?
How convenient for the cause.
Please provide observational evidence that the regional cooling and warming of the ocean in the last few decades that yielded a net 0.02°C change in ocean temperature (a) falls outside range of natural variability, and (b) was not affected by cloud radiative forcing (a reduction of low cloud cover in the tropics).
Considering the ocean temperatures have only changed by a net 0.1°C in the last 50 years, and that ocean temperatures have previously changed naturally at rates substantially greater than that, it’s probably going to take a lot to convince us that there is something unusual happening today.
SebastianH, what are you serious?
<em<"There is no history of a CO2 increase caused by humans that we can compare the current situation too."
True, because mankind’s influence on this planets climate is vanishingly small. CO2 is a very, very minor gas in the atmosphere. Minuscule CO2 increase caused by humans eh? Your evidence is as always lacking.
Do changes in atmospheric CO2 do anything but help the biosphere thrive? See https://www.nasa.gov/feature/goddard/2016/carbon-dioxide-fertilization-greening-earth/ . There is no evidence of scary, alarming temperature effects you attempt to insinuate without evidence. Our atmospheric CO2 levels are at such a low percentage of the atmosphere, many other chaotic processes ensure any (presumed) CO2 thermal effects are buried in the noise of climate change, and not in control of it — ice-core, mud-core and so many scientific studies show this.
“Yeah if you consider humans to be a result of nature, then of course it is all natural. Otherwise, there is no indication that the increase in global temperatures in the last few decades is natural in the sense that it would have happened anyway, e.g. if we would not have been living on this planet.”
So SebastianH, you do understand but fatuously deny it!
(Or am I being deliberately obtuse just to annoy you with your dull remarks?) However it is obvious from that dull remark, you apparently can not consider any research on the state of the planet’s temperature, atmosphere, biosphere, or climate before humans proliferated, e.g. before 300 years ago. You only consider what has happened very recently (the last 100 years or so). That’s not exactly scientific now is it?
SebastianH just proffers more empty remarks.
“Is there any threshold that when surpassed you’ll consider the change “not natural”? What would it take? A warming of 2°C? 3°C? More?”
Another hypothetical question.
Overall, within the hypothetical nature of this question there is no temperature, cold or hot that would not be natural.
However within the reality of the current situation 1°C in 100 years is neither alarming nor unusual, it IS quite within normal historical and natural variation limits.
Of course if you have any evidence to say it is not, please step up to the plate and present it.
Kenneth,
A conspiracy, for sure …
a) flawed logic, if something happened before for another cause that doesn’t mean it is happening now for the same cause.
b) how are clouds not a feedback of the climate? How can they be a cause? That only works in your world where cosmic rays control the cloud cover. Please answer:
1) how can something that influences about 5% of the cloud cover change according to papers your posted influence the complete cloud cover this way?
2) if cosmic rays could control the cloud cover this way, why did it get warmer when the Sun got weaker (and cosmic rays got stronger as a result)?
So you need the full-blown realization of what a human-caused climate change could end up to be if we continue on a path similar to RCP8.5?
This “it happened before and to a greater extent” thing is not a valid argument against something happening now for a known reason.
tomOmason, you are the guy who thinks the definition of the second is circular. Your interpretation of science has no value to me. Feel free to continue that “CO2 is a very, very minor gas in the atmosphere. Minuscule CO2 increase caused by humans eh?” theme though … on one hand tiny and on the other hand it is helping the biosphere to thrive. This cognitive dissonance must be hard to justify.
The uncertainties of the past left aside, why do you think that looking at the past and being in awe about far greater climate changes does anything to make the current one silently go away?
What you do is unscientific. Not looking at mechanisms, but assuming it is all periodic and climate will just continue on its periodic path. Or did I missunderstand you again, because you tried to be extra dull to annoy me?
Ok, let’s say you could live until 2100 and you could witness a warming of 2 or 3 degrees compared to pre-industrial levels and everything that came with it. Would you then say in hindsight, that you were wrong? Or would that also be just natural climate change?
P.S.: How are you so sure that “it IS quite within normal historical and natural variation limits”? Where is the skepticism towards those that provide you with this view of the world? How far back do you have to go to find larger and faster increases?
I didn’t call it a conspiracy that your positions are based on very short-term data. Why do you?
The same flawed logic goes the other way too: Climate change causes can be the same today as they have been in the past.
You’ve not heard of cloud radiative forcing before?
http://science.sciencemag.org/content/243/4887/57
Cloud-Radiative Forcing and Climate: Results from the Earth Radiation Budget Experiment
“The size of the observed net cloud forcing is about four times as large as the expected value of radiative forcing from a doubling of CO2. The shortwave and longwave components of cloud forcing are about ten times as large as those for a CO2 doubling.”
“CLOUDS ARE REGULATORS OF THE RADIATVE HEATING OF the planet. They reflect a large part of the incoming solar radiation, causing the albedo of the entire earth to be about twice what it wouild be in the absence of clouds (1). Clouds also absorb the longwave (LW) radiation (also known as infrared or thermal radiation) emitted by the warmer earth and emit energy to space at the colder temperatures of the cloud tops. Cloud LW absorption and emission are, in a sense, similar to the radiative effects of atmospheric gases. The combined effect of LW absorption and emission-that is, the greenhouse effect-is a reduction in the LW radiation emitted to space. The greenhouse effect of clouds may be larger than that resulting from a hundredfold increase in the CO2 concentration of the atmosphere.”
—
http://www.sciencemag.org/content/295/5556/841
“It is widely assumed that variations in Earth’s radiative energy budget at large time and space scales are small. We present new evidence from a compilation of over two decades of accurate satellite data that the top-of-atmosphere (TOA) tropical radiative energy budget is much more dynamic and variable than previously thought. Results indicate that the radiation budget changes are caused by changes in tropical mean cloudiness.”
Although more and more scientific study is underway, cloud cover changes as they relate to cosmic ray fluctuations are still in the process of being developed. This is not a “settled science” topic.
If cosmic rays have little to no effect on cloud cover, do you believe that human CO2 emissions control changes in cloud cover?
Well, I would think that it would first be nice to have it established that a net 0.02 C change of ocean temperature during 1994-2013 (Wunsch, 2018) is unusual and falls outside the range of what can and does occur naturally, or without CO2 emissions changes. Indications to date suggest this kind of change is not unusual, though. But if that (0.01 C/decade changes are unusual and likely unnatural) ever is established, I’d still need to have it verified that the reason why the ocean temperatures changed by 1/100th of a degree per decade is attributable to one factor – human CO2 emissions. We’d need physical measurements, controlled experiments, and we’d especially need to rule out changes in other factors that contribute to ocean temperature changes (like cloud radiative forcing). Once these lines of evidence have been addressed using the scientific method, perhaps then we can consider the catastrophic doomsday scenarios as they relate to CO2 emissions that you believe in.
NO evidence of CO2 warming anything, anywhere, anytime.
Until you can produce evidence, your ranting and raving is nothing but a waste of space and time
Mindless trolling is your ONLY reason for being here.
Q1. In what way has the climate changed in the last 40 years, that can be scientifically attributable to human CO2 ?
Q2. Do you have ANY EMPIRICAL EVIDENCE at all that humans have changed the global climate in ANYWAY WHATSOEVER?
SebastianH, congratulations you have confirmed what I suspected of you. I have awaited this moment with relish!
You are so pompously arrogant that you believe that only those who are at your perceived level of knowledge (flawed as it is) can question you. You’re a snob!
Your comment “tomOmason, you are the guy who thinks the definition of the second is circular. Your interpretation of science has no value to me. “
Your reaction is exactly as I suspected, (“Your interpretation of science has no value to me”) you have passed my test. You believe that those that wish to argue with you about your flawed ideas must reach some imaginary status level. You will not converse with those you believe are below you! You’re a snob! An arrogant scientifically and mathematically illiterate snob!
Well I quite deliberately failed so as to watch your reaction. And yes true to form your great egotistical bladder of snobbery has burst out, just as you’ve shown towards others.
Your comment shows exactly who you are!
You do not want a debate.
You do not want learn.
You do not want to teach.
You just try to promulgate and propagandizes the IPCC message with no real understanding of it.
Sad snob SebastianH!
You don’t reply with any science because you can not!
You have no science, no scientific mind, only the snobbish arrogance of a demented true religious believer, ritually chanting his mantra.
@spike:
You write to SebH – “Here’s a great chance for you to do some cherry picking.”
And he gladly obliges, by citing an alleged 1 Deg C temperature anomaly rise at “a rural site (ID 3015).”
OK, we can now close all our other weather stations. We’ve found our most favored proxy location for “global” temperature anomalies.
He’s not often amusing, but when he … is you’ll miss it if you blink.
I pointed him to a source for station data of the DWD (German weather service). Not going to do the work for him. If he (and you) think(s) that I cherry-picked the one station that shows warming … feel free to analyze all the other stations.
Q1. In what way has the climate changed in the last 40 years, that can be scientifically attributable to human CO2 ?
Q2. Do you have ANY EMPIRICAL EVIDENCE at all that humans have changed the global climate in ANYWAY WHATSOEVER?
@spike55 14. August 2018 at 9:18 PM
It’s not clear to me if the “data” he wants us to be amazed by is raw or “adjusted(**).” And, of course, given his history of slovenly research, I seriously doubt that he knows how to present it, even if he can find the appropriate documentation.
As important as that information is to us, he should already know what we want to see to confirm its validity. The fact that he doesn’t make the effort tells me he has no idea what scholarship is, and could care less about acquiring that skill. Not well educated, and without any self discipline at all. I.e., typical activist troll.
(**)I found these two on German temperatures derived from “homogenized radiosonde data.”
https://journals.ametsoc.org/doi/full/10.1175/JCLI-D-14-00814.1
https://journals.ametsoc.org/doi/pdf/10.1175/JCLI-D-14-00814.1
I don’t have time now, but if you want to play with it, here’s what appears to be a source of data worldwide, or so they say.
https://www7.ncdc.noaa.gov/CDO/cdoselect.cmd?datasetabbv=GSOD&countryabbv&georegionabbv
[…] Not Tricks Zone highlights hot weather hysteria […]
And don’t forget how global warming is changing the habits of migratory birds. They are so confused, and it’s all YOUR fault! 😉
http://4.bp.blogspot.com/_VvDvGolaKsU/SwRSFP3BqGI/AAAAAAAAAjQ/Sa_0T7aOZ2Y/s1600/migratory.jpg
Goodonya Yonason. There it is in black and white, err…+ blue (sky).
Oops, meant to include the source for that, which is first post here (18-NOV-2009)
http://jimpeden.blogspot.com/2009/11/norm-kalmanovich-on-global-warming-hoax.html
More good stuff at that link to.